Overview
In the modern AI era, let’s implement machine learning simply by ourselves.
Machine learning
In this machine learning, we will classify images.
Let’s see an example.
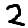
You can probably tell that this number is “2” at a glance.
If a machine can correctly determine that this number is “2” in the same way, wouldn’t that be great?
ALPAKA: I don’t think so
Why can we tell that this number is “2” in the same way?
It’s because we’ve always known that “something like this is 2”.
Similarly, if we teach the computer, it will learn by itself.
That’s machine learning.
This time, we’ll create a program that recognizes the numbers we wrote ourselves.
Before we start
I’m not very familiar with machine learning, so there may be mistakes in what I’m saying here.
If there are mistakes, please let me know via the email address of my github account.
Before we start
This time, we’ll use python for machine learning.
Also, this article was implemented on Ubuntu on wsl.
I also tested it with docker.
Let’s install python.
If you don’t use a version management tool,
apt update
apt -y upgrade
apt install python3 pip
You may need to add sudo to the command since usually we do not run commands as root.
At least in my environment, when installing python3, I was asked for the region.
Let’s check if python3 and pip are installed.
$ python3 --version
Python 3.12.3
$ pip --version
pip 24.0 from /usr/lib/python3/dist-packages/pip (python 3.12)
Let’s install the necessary packages.
pip install opencv-python tqdm numpy matplotlib tensorflow
opencv is used for image reading, tqdm is used for progress bar display, numpy is used for array creation, matplotlib is used for image display, and tensorflow is used for machine learning model creation.
This is the environment we need.
Creating handwritten digit data
The handwritten digit data is included in the module, but this time we will create the data ourselves without using it.
I used the standard app “Paint” on windows to write the number in 28px by 28px.
In this program, we will assume that there is a directory called data under the same directory as the python file for learning, and that there is a directory for each number under the directory.
That is,
.
`-- data
|-- 0
| `-- 1.png
|-- 1
| `-- 1.png
|-- 2
| `-- 1.png
|-- 3
| `-- 1.png
|-- 4
| `-- 1.png
|-- 5
| `-- 1.png
|-- 6
| `-- 1.png
|-- 7
| `-- 1.png
|-- 8
| `-- 1.png
`-- 9
`-- 1.png
Also, we will proceed with the assumption that the image is black and white this time.
Program creation
Let’s create a program using your favorite editor.
I named the program train.py.
First, let’s import the necessary modules.
import cv2 as cv
import random
import tqdm
import os
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
Next, let’s create the model.
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(units=200, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(units=100, activation=tf.nn.relu))
model.add(tf.keras.layers.Dense(units=10, activation=tf.nn.softmax))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Here, we declare the model in the first line, add layers from the second to the fifth line, and compile it in the last line.
I’ll talk about what layers are in the next article.
Next, let’s read the photos we want to learn from the directory.
files = []
for i in range(0, 10):
path = f"./data/{str(i)}/"
tmpfiles = os.listdir(path)
tmpfiles = [path + j for j in tmpfiles]
files = files + tmpfiles
random.shuffle(files)
The reason we shuffle randomly at the end is to make the model generated every time different.
Let’s make the machine learn.
This time, we won’t read all the pictures at once, but we’ll read them little by little when we need them.
It’s because we don’t want to load all the pictures into memory if we can’t.
MAX_PICTURE = 100000 # How many pictures to load into memory at once
EPOCH = 100 # How many times to learn the pictures
nowindex = 0 # What index we've reached
for i in tqdm.tqdm(range(EPOCH)):
nowindex = 0
train_x = []
train_y = []
while True:
filepath = files[nowindex]
img = cv.imread(filepath)[:, :, 0]
img = np.invert(img)
train_x.append(img) # Add the image to the array
train_y.append(int(filepath[7])) # Add the number to the array
nowindex += 1
if len(train_x) >= MAX_PICTURE or nowindex >= len(files):
train_x = np.array(train_x) # Convert to numpy array
train_y = np.array(train_y) # Same as above
model.train_on_batch(train_x, train_y) # Learn
train_x = []
train_y = []
if nowindex >= len(files):
break
model.save("model.h5") # Save the created model
It’s a bit long, but it’s like this.
I used tqdm, which displays a progress bar, because if we just loop, we can’t see the progress.
The last line saves the completed model.
This is train.py.
Let’s run it here for now.
python3 train.py
My environment has a GPU driver, so it took about 30 seconds.
Next, let’s check how accurate this model is.
Personally, I think it’s good if it exceeds 95%.
I assume that the test data is arranged as follows.
test
├── 0-0.png
├── 0-1.png
├── 1-0.png
├── 1-1.png
├── 2-0.png
├── 2-1.png
├── 3-0.png
├── 3-1.png
├── 4-0.png
├── 4-1.png
├── 5-0.png
├── 5-1.png
├── 6-0.png
├── 6-1.png
├── 7-0.png
├── 7-1.png
├── 8-0.png
├── 8-1.png
├── 9-0.png
├── 9-1.png
The number before the hyphen is what is actually written, and the number after is just to avoid name conflicts.
Let’s implement it.
import cv2 as cv
import numpy as np
importatplotlib.pyplot as plt
import tensorflow as tf
import os
model = tf.keras.models.load_model('model.h5', custom_objects={'softmax_v2': tf.nn.softmax}) # Load the model
test_x = []
test_y = []
for i in os.listdir("./test/"):
img = cv.imread("./test/" + i)[:, :, 0]
img = np.invert(img)
test_x.append(img)
test_y.append(int(i[0]))
loss, accuracy = model.evaluate(test_x, test_y)
print("loss: ", loss)
print("accuracy: ". accuracy)
This is how we can check the accuracy.
Now, let’s have the machine predict the number we wrote.
model = tf.keras.models.load_model('model.h5', custom_objects={'softmax_v2': tf.nn.softmax})
img = cv.imread(path)[:, :, 0]
img = np.invert(np.array([img]))
prediction = model.predict(img)
print(prediction)
This is how we can display the probability of each number.
If you want to display only the number with the highest probability, execute
print(np.argmax(prediction))
Let’s try it
I also tried it.
The result was about 92%.
I didn’t get as much accuracy as I thought, but since the learning data is less this time, I’ll leave it at this.
Next time, I’ll write an article about the neurons.